LLMs as Agents on Knowledge Graphs for Domain-Specific Dialogues
See the code on GitHubFor my Master's thesis, I built... yes, yet another AI chatbot.
I know, I know. In an era where a new RAG-based AI Assistant drops every five minutes, adding another chatbot to the pile might not seem groundbreaking at first glance. But don't let the buzzwords fool you—this isn't your standard vector-database wrapper.
I set out to investigate, implement, and evaluate a paradigm called Think-on-Graph (ToG), which treats LLMs as agents and knowledge graphs (KGs) as an interactive environment. The agent traverses the graph to collect relevant knowledge triples before synthesizing an answer.
Before we dive into the architecture, here is the final result in action, tackling an Obama-related question. I don't know why but Obama examples are pretty common in this research domain.
Static Brains and External Knowledge
LLMs are undeniable powerhouses, but out of the box, their knowledge is frozen in time. If you ask them about private data, niche domains, or recent events, they tend to hallucinate. Fine-tuning is one fix, but it is expensive, rigid, and still leaves you with a black box where humans cannot verify the model's reasoning. The most practical alternative is providing external knowledge to the model's context window. There are various ways to do that:
- Long context (the brute-force approach)
Shoving an entire dataset into an expanding context window is a simple solution. However, it usually overwhelms the model, making it lose focus on critical facts and creating a "needle in a haystack" problem. - Vector RAG
The industry standard works beautifully when an answer is neatly contained within a single chunk. However, if the query requires multi-hop reasoning or logical deduction across scattered facts, traditional semantic search hits a wall. - Graph RAG
While leveraging KGs helps, most approaches separate the retrieval process (like generating a SPARQL query) from the actual reasoning. This forces a heavy reliance on the quality and completeness of the graph or deep prior knowledge of its schema. However, KGs enable intuitive reasoning over entities and relationships. ToG capitalizes exactly on this fact.
The Think-on-Graph Way
Introduced by Sun et al., ToG acts as a plug-and-play framework that drops an LLM into a KG it has zero prior knowledge about. Given a user prompt, the LLM agent starts from initial nodes and then iteratively traverses the graph based on helpful knowledge gathered along the paths. Once the agent finds the answer (or exhausts its traversal budget) it synthesizes a response using the gathered facts. If the graph yields nothing, it simply falls back on its own encoded knowledge.
Because the knowledge is entirely decoupled from the model, you can swap or update the KG in real-time. Better yet, the traversal process forces the LLM to leave a step-by-step trail of its reasoning.
Formatted Think-on-Graph
While the original ToG concept is an interesting idea, the implementation had limitations. I engineered an optimized version called Formatted Think-on-Graph (FormaToG) to address three major bottlenecks:
- From Rigid to Plug-and-Play
The original code was tightly coupled to specific LLM APIs and public graphs like Wikidata. I decoupled the architecture using abstract classes, making it trivial to integrate any new LLM API or graph database. - From Free-Text to Strict Schemas
The original system relied on unstructured prompts, asking models to dump answers into curly braces. This broke constantly, especially on smaller models. I completely redesigned the prompt pipeline using meta-prompting and strict JSON schemas, drastically improving retrieval robustness. - From Flawed Scoring to Simple Selection
The original algorithm used a scoring mechanism to guide traversal, but a logical flaw occasionally caused arbitrary navigation. I replaced this with a selection-based mechanism that eliminated the logical errors and reduced the number of agent calls needed.
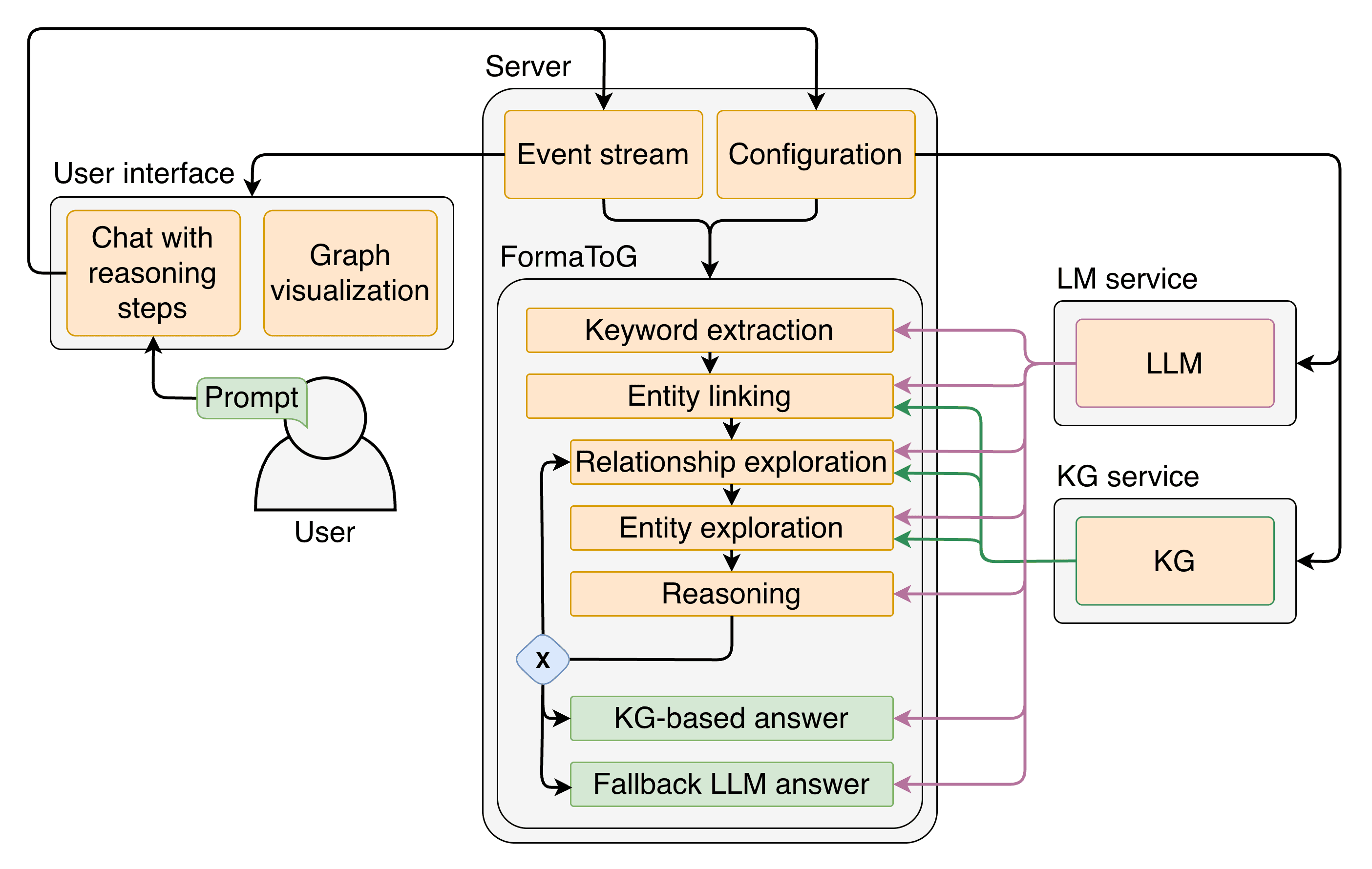
The figure above illustrates the architecture of the chatbot I built around FormaToG: When a user submits a prompt, a FastAPI server spins up FormaToG in a background process. As the agent traverses the graph, both its intermediate reasoning steps and the final answer are streamed to the client via server-sent events. The frontend is a React application that displays the chat alongside a real-time visualization of the graph traversal using Reagraph. Out of the box, I’ve pre-implemented interfaces for Ollama, Google, Wikidata, and Neo4j.
Evaluation
To empirically measure the performance of FormaToG, I ran a question-answering benchmark against a reimplementation of the original ToG, Chain-of-Thought (CoT), and standard Input-Output (IO) prompting. I evaluated them on two public datasets (QALD-10 and CWQ) and one custom domain-specific dataset (LNDW25), which I built by scraping data from the Berlin science event "Lange Nacht der Wissenschaften 2025" and auto-generating a fresh KG. Llama models are free to use and open-access. I used three models of distinct classes:
llama3.1:8b(small LLM)llama3.3:70b(medium LLM)llama4:scout(small to medium Mixture-of-Experts)
I ran the experiments on my university's HPC cluster.
Due to a high demand for resources and limited GPU availability, only llama3.1:8b was evaluated on CWQ, and llama4:scout was the largest model I could include.
The results look good. To measure performance, I relied on the F1 score, which calculates the overlap between what the model predicted and the dataset's gold-standard answer. Take a look.
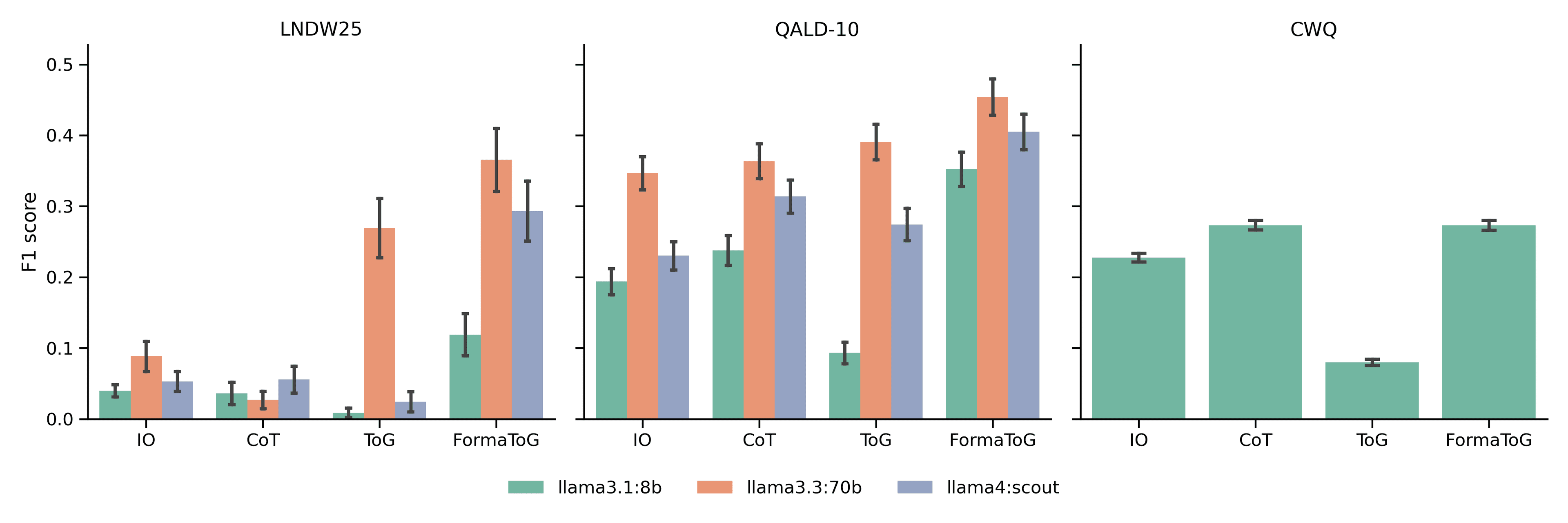
FormaToG doesn't just outperform the baselines—it gives smaller models superpowers.
On the QALD-10 dataset, equipping the lightweight llama3.1:8b with FormaToG allowed it to beat the standard llama4:scout and perform on par with the massive llama3.3:70b.
Furthermore, while the original ToG completely choked on the domain-specific LNDW25 dataset unless paired with a massive 70B model, FormaToG handled the unseen, niche data gracefully across the board.
Unsurprisingly, the prompt-only baselines completely collapsed on the LNDW25 dataset, perfectly illustrating the fatal flaw of relying solely on a model's frozen internal knowledge.
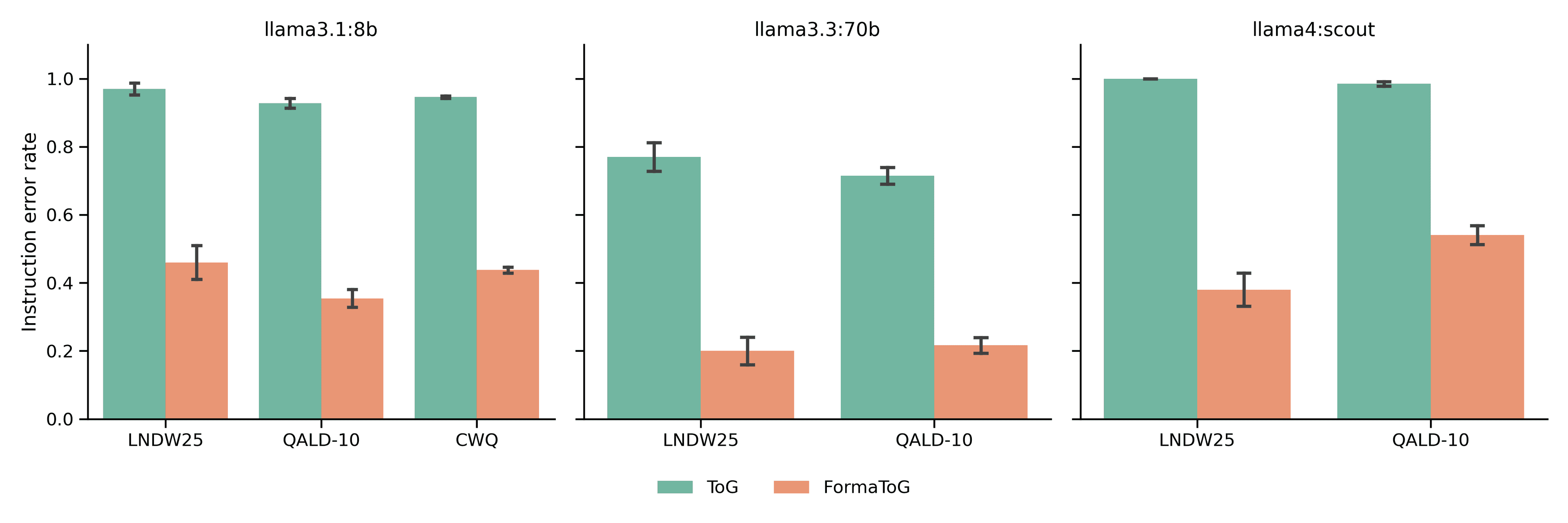
Beyond accuracy, this figure below highlights a crucial secondary win:
FormaToG forces models to follow instructions much more precisely than ToG.
Zero fine-tuning. Zero retraining. Just drop in the model, hook up your graph, and let the agent do the thinking.